Chapter 7 Week 6 meeting: using ggplot2
Today we are going to do a super brief review of the book chapter, namely just this template:
ggplot(data = <DATA>) + # DATA is a tibble of data *in long (tidy) format*
<GEOM_FUNCTION>( # geom_point(), geom_bar(), geom_histogram(), etc.
# each geom_function output gets layered on top of the last!
mapping = aes(<MAPPINGS>), # mappings wrapped up in the aes() function
stat = <STAT>, # usually can be avoided if the default is used
position = <POSITION> # dodge, stack, jitter...
) +
<COORDINATE_FUNCTION> + # coord_flip(), or coord_quickmap(), or other things to set scales.
<FACET_FUNCTION> # facet_grid() or facet_wrap()And now we are going to launch directly into having everyone try this out on their own.
Here is a data set of simulation results:
library(tidyverse)
sims <- readRDS("inputs/alewife_snps_100_of_200.rds")That looks like this:
sims## # A tibble: 700 x 6
## iter repunit true_rho rho_mcmc rho_bh rho_pb
## <int> <fctr> <dbl> <dbl> <dbl> <dbl>
## 1 1 CAN 0.04573827 0.06489907 0.04550360 0.06226238
## 2 1 NNE 0.06962820 0.07385272 0.05886538 0.06360804
## 3 1 MB 0.14588315 0.21344097 0.21242781 0.22291767
## 4 1 NUN 0.46891013 0.14646259 0.35338886 0.24710874
## 5 1 BIS 0.06644381 0.09336929 0.15767998 0.08005169
## 6 1 LIS 0.15719031 0.35012560 0.11664560 0.27002139
## 7 1 MidAtlantic 0.04620614 0.05784975 0.05548877 0.05403009
## 8 2 CAN 0.02751659 0.02866411 0.02224521 0.02645824
## 9 2 NNE 0.23190134 0.27633524 0.20446014 0.26219858
## 10 2 MB 0.16320168 0.07701908 0.17914736 0.11657221
## # ... with 690 more rowsWhat we have here is a true proportion (true_rho) that was simulated (100 iterations for each of 7 repunits), and then we have estimates of that proportion using different methods (rho_mcmc, rho_bh, and rho_pb).
We want to compare the different types of estimated rho’s to the true_rho for each repunit.
But before we do this, there is one more thing we need to know about ggplot: like most of the tidyverse tools, it doesn’t like having multiple columns of the same variable. What do we mean by that? Well, rho_mcmc, rho_bh, and rho_pb are all just different flavors of a variable we might call estimated_rho.
We won’t get to it this quarter, but everyone should read the Tidy Data chapter. It will show how and why we would want to tidy our data to look like this:
tidy_sims <- sims %>%
tidyr::gather(data = ., key = "estimation_method", value = "estimated_rho", rho_mcmc:rho_pb)
# see what that looks like:
tidy_sims %>%
arrange(iter, repunit, estimation_method)## # A tibble: 2,100 x 5
## iter repunit true_rho estimation_method estimated_rho
## <int> <fctr> <dbl> <chr> <dbl>
## 1 1 CAN 0.04573827 rho_bh 0.04550360
## 2 1 CAN 0.04573827 rho_mcmc 0.06489907
## 3 1 CAN 0.04573827 rho_pb 0.06226238
## 4 1 NNE 0.06962820 rho_bh 0.05886538
## 5 1 NNE 0.06962820 rho_mcmc 0.07385272
## 6 1 NNE 0.06962820 rho_pb 0.06360804
## 7 1 MB 0.14588315 rho_bh 0.21242781
## 8 1 MB 0.14588315 rho_mcmc 0.21344097
## 9 1 MB 0.14588315 rho_pb 0.22291767
## 10 1 NUN 0.46891013 rho_bh 0.35338886
## # ... with 2,090 more rowsSee that we have taken the three columns of estimates and put them int he estimated_rho column, and we are using the estimation_method column to say which method was used for each row of values in estimated_rho.
You can download that tidy_sims tibble from here.
Now, we could start by making a scatter plot of estimated versus true rho with ggplot. That would look like this:
ggplot(tidy_sims, aes(x = true_rho, y = estimated_rho)) +
geom_point()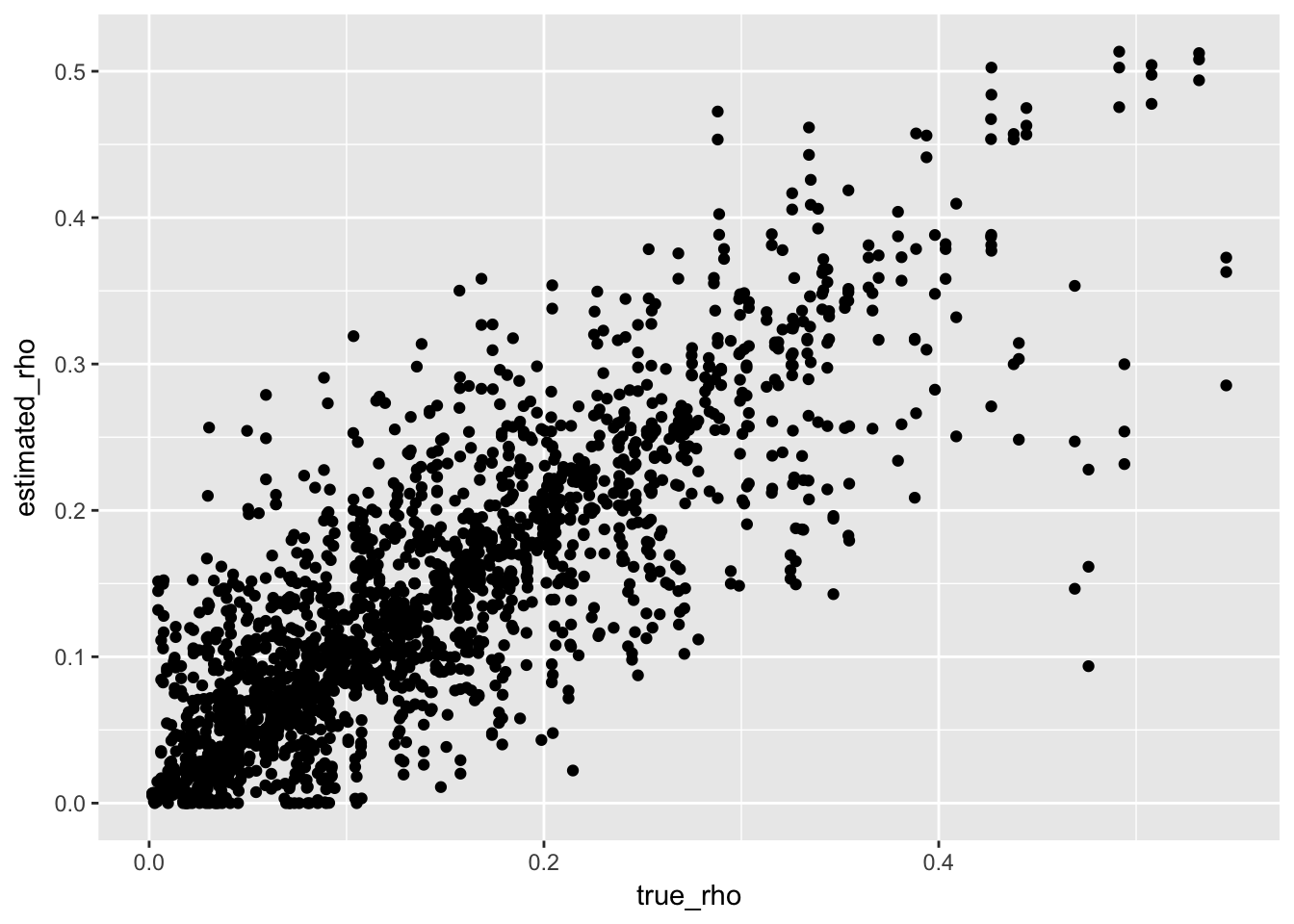
OK, that is relatively uninformative. How about we spice it up a bit to make this: 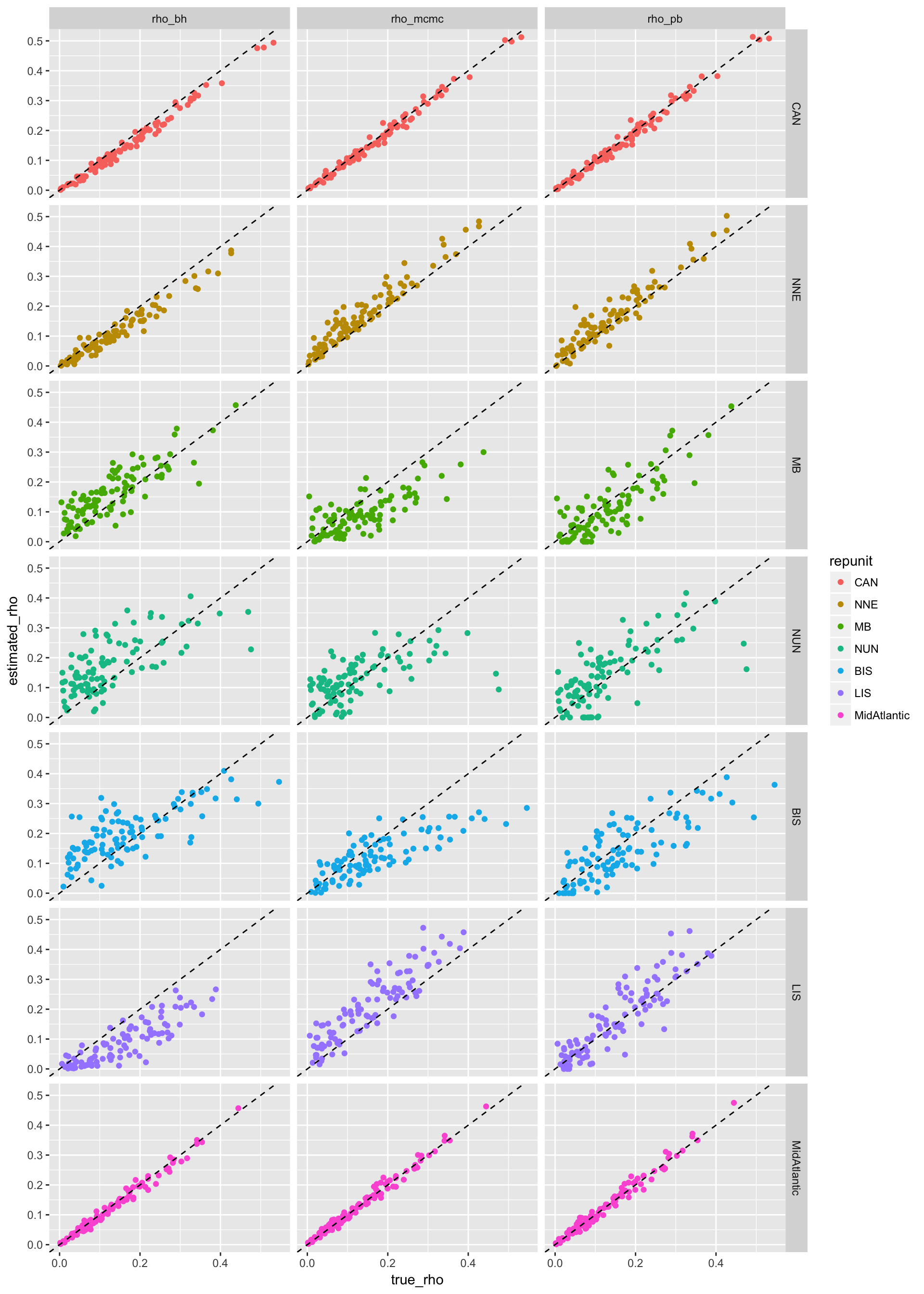
7.0.1 Your Mission
OK Class! Here is your mission.
- Download
tidy_simsand figure out during our class time how to make the above plot.
Hints: you will be using thecolouraesthetic, ageom_abline()geom, and alsofacet_grid() - When you have finished that, use your newly-acquired ggplot skills to make an informative plot from your own data set.
I will be here in class to help with this and field any questions.
7.1 Some lecture notes from a few years ago
This is just a rewrite of some playing with ggplot that I did for the reproducible research course a few years ago, updated to the tidyverse.
It might be worth a reading through to see more examples ### Prerequisites {#ggplot-prereq} * To work through the examples you will need another package that you might not have yet. * Please download/install these before coming to class: 1. install necessary packages:
```r
install.packages("lubridate")
```
2. Pull the most recent version of the rep-res-course repo just before coming to class.7.1.1 Goals for this hour:
- Describe (briefly)
ggplot2s underlying philosophy and how to work with it. - Quickly overview the _geom_s available in
ggplot2 - Develop an example plot together
- Turn you all loose with the
mosaicpackage to experiment with different plots
7.2 About ggplot2
7.2.1 Basics
- A package created by Hadley Wickham in 2005
- Implements Wilkinson’s “grammar of graphics”
- Unified way of thinking about 2-D statistical graphics
- Not entirely easy to learn
- if you already know R’s base graphics system, it is painful to re-learn a different way of doing things
- if you don’t already know how to do graphics in R, be glad.
- regardless it is worth learning ggplot
- I am not even going to teach R’s base graphics system
- Amazing for quick data exploration and also produces publication quality graphics
- Support for legends etc., considerably better/easier than R base graphics
7.2.2 What is this grammar of graphics?
- Traditionally, people have referred to plots by name
- i.e., scatterplot, histogram, bar chart, bubble plot, etc.
- Disadvantages:
- Lots of possible graphics = way too many names
- Fails to acknowledge the common elements / similarities / dissimilarities between different plots
- Wilkinson’s Grammar of Graphics (a book) describes a few building blocks which when assembled together in particular ways can generate all these named graphics (and more)
- Provides a nice way of thinking about and describing graphics
7.2.3 ggplot2
- Hadley Wickham’s R implementation of a modified (layered) grammar of graphics
ggplotandggplot2are similar. `ggplot2is just more recent (and recommended)ggplotoperates on data frames- in R base graphics typically you pass in vectors
- in
ggploteverything you want to use in a graphic must be contained within a data frame - Takes getting used to, but ultimately is a good way of thinking about it.
7.2.4 Components of the grammar of graphics
- data and aesthetic mappings
- geoms (geometric objects)
- stats (statistical transformations)
- scales
- coords (coordinate systems)
- facets (a specification of how to break things into smaller subplots)
We will focus on 1, 2 for most of today.
7.2.5 In a nutshell
Without getting into the complications of scales and coordinate systems here, in a nutshell, is what ggplot does:
- Layers in plots are made by:
- mapping values in the columns of a data frame to aesthetics, which are properties that can visually express differences, for example:
- \(x\)-position
- \(y\)-position
- shape (of a plot character, for example)
- color
- size (of a point, for example)
- Portraying those values by drawing a geometric object whose appearance and placement in space is dictated by the mapping of values to aesthetics.
- mapping values in the columns of a data frame to aesthetics, which are properties that can visually express differences, for example:
7.3 An example, please
Phew! That is a crazy mouthful. Is this really going to help us make pretty plots?
All I can say is you owe it to yourself to persevere — ggplot2 is really worth the effort!
7.3.1 A pole vaulting example
- Here is a concrete example: we will investigate the history of pole-vaulting world records
- I grabbed the data by copying them from http://en.wikipedia.org/wiki/Men's_pole_vault_world_record_progression and pasting them into a text file
- Here we make a data frame out of them:
library(tidyverse) # for dealing with dates
library(stringr)
library(lubridate) # functions mdy, ymd, today(), etc.##
## Attaching package: 'lubridate'## The following object is masked from 'package:base':
##
## date# first off read the data into a data frame
pv <- read_tsv("inputs/mens_pole_vault_raw.txt", comment = "%") %>%
mutate(Date = lubridate::mdy(str_replace(Date, "\\[[0-9]\\]", ""))) %>% # clean up dates
mutate(Meters = parse_number(Record)) # get the record in a numeric number of meters## Parsed with column specification:
## cols(
## Record = col_character(),
## Athlete = col_character(),
## Nation = col_character(),
## Venue = col_character(),
## Date = col_character(),
## `#[2]` = col_integer()
## )- Great, what do these look like? Try
View(pv)if you are following along. Here are the first few rows too:
pv## # A tibble: 72 x 7
## Record Athlete Nation Venue Date
## <chr> <chr> <chr> <chr> <date>
## 1 4.02 m Marc Wright United States Cambridge, U.S. 1912-06-08
## 2 4.09 m Frank Foss United States Antwerp, Belgium 1920-08-20
## 3 4.12 m Charles Hoff Norway Copenhagen, Denmark 1922-09-22
## 4 4.21 m Charles Hoff Norway Copenhagen, Denmark 1923-07-22
## 5 4.23 m Charles Hoff Norway Oslo, Norway 1925-08-13
## 6 4.25 m Charles Hoff Norway Turku, Finland 1925-09-27
## 7 4.27 m Sabin Carr United States Philadelphia, U.S. 1927-05-27
## 8 4.30 m Lee Barnes United States Fresno, U.S. 1928-04-28
## 9 4.37 m William Graber United States Palo Alto, U.S. 1932-07-16
## 10 4.39 m Keith Brown United States Boston, U.S. 1935-06-01
## # ... with 62 more rows, and 2 more variables: `#[2]` <int>, Meters <dbl>7.3.2 A first ggplot
- There is a simplified ggplot function called
qplotthat behaves more like R’s base graphics functionplot().- I don’t recommend
qplot. It will just lengthen the time it takes to understand the grammar of graphics. - Instead, we will use the full
ggplot()standard syntax.
- I don’t recommend
First we have to essentially establish a plotting area upon which to add layers. We will do this like so:
g <- ggplot()At this point,
gis a ggplot plot object. We can try printing it:g That doesn’t work, because there is nothing to plot. We have to add a layer to it.
That doesn’t work, because there is nothing to plot. We have to add a layer to it.Adding a layer is done by adding a collection of geometric objects to it using one of the
geom_xxxxfunctions. Each such function requires a data set and a mapping of columns in the data set to aesthetics. Let’s make some scatter-points: Meters as a function of Date:g2 <- g + geom_point(data = pv, mapping = aes(x = Date, y = Meters)) g2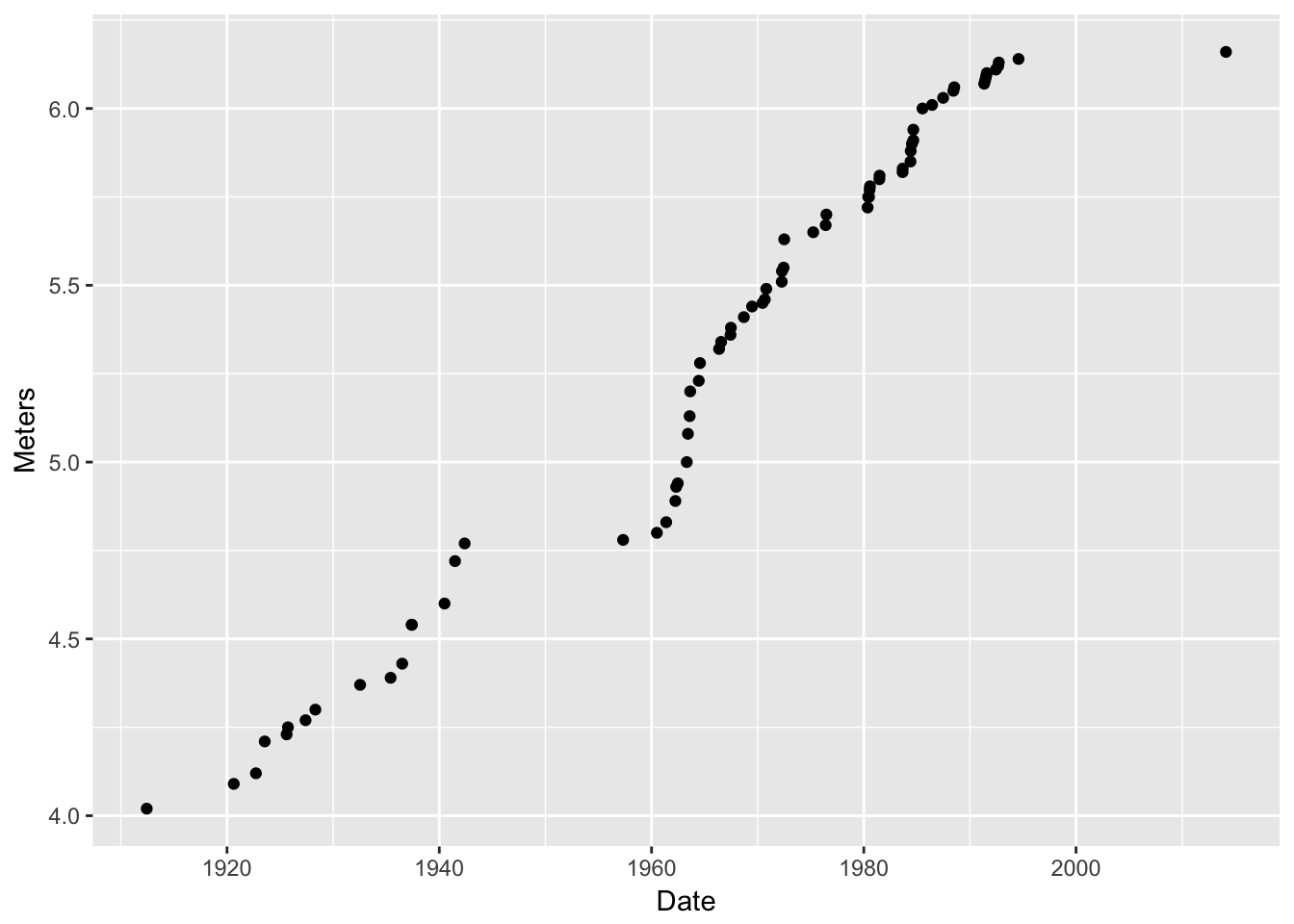
Wow! That totally worked. Here are some interesting points about:
g2 <- g + geom_point(data = pv, mapping = aes(x = Date, y = Meters)) g2- You add layers by catenating them with
+. - the names of the columns don’t need to be quoted.
- when you map aesthestics you wrap them inside the
aes()function - the full object with all the layers is returned into
g2and then we printed it (by typingg2). (we could have also just saidg + geom_point(data = pv, mapping = aes(x = Date, y = Meters))) - we didn’t have to do anything fancy to the dates…ggplot knew how to plot them. This is thanks to turning the dates into
lubridateobjects. (If you work with dates, get to know the lubridate package!)
- You add layers by catenating them with
I want to overlay a line on that…No problem! Add another layer:
g3 <- g2 + geom_line(data = pv, mapping = aes(x = Date, y = Meters)) g3
That worked! We just added (literally, using a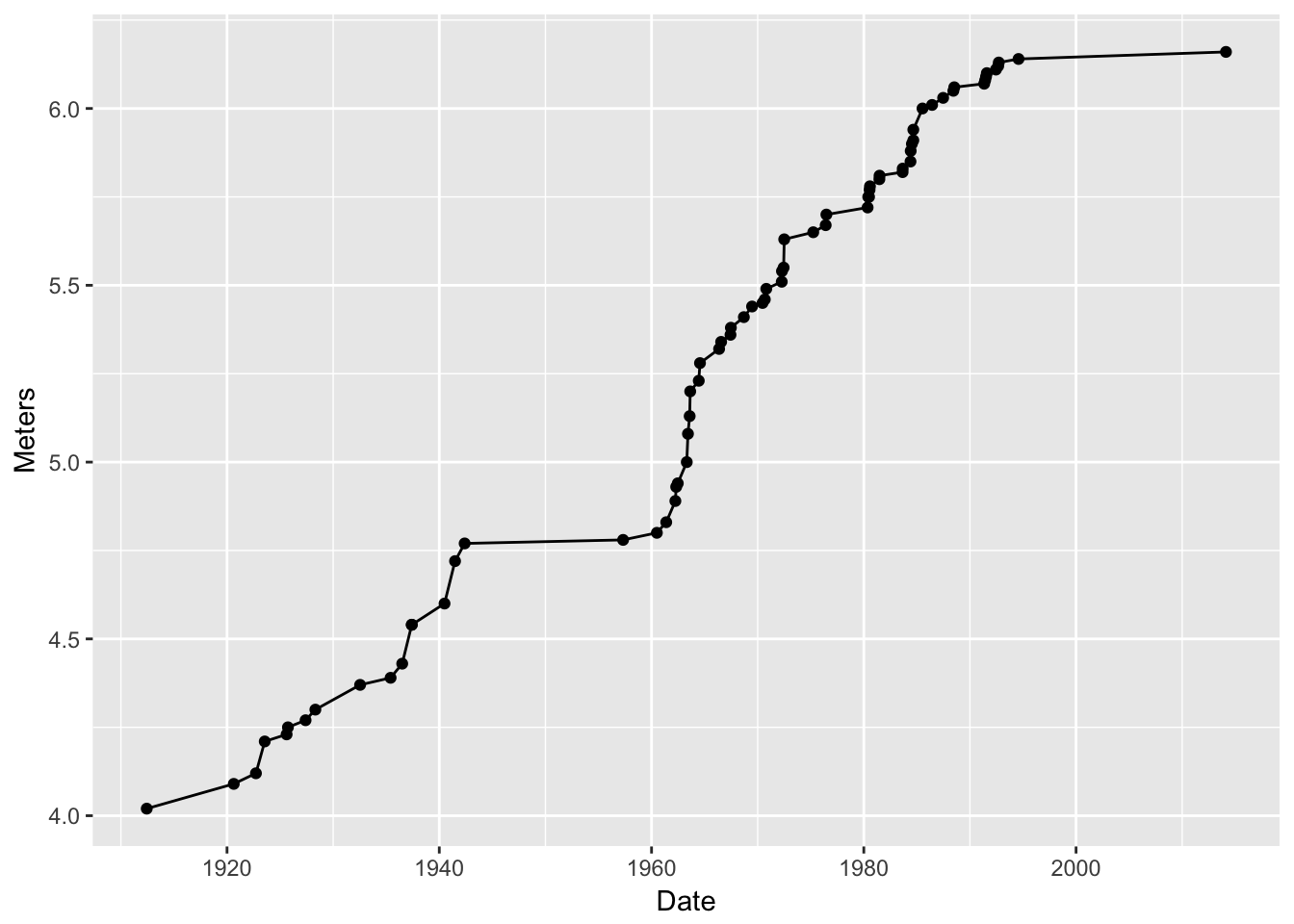
+sign!) another layer—one that had a line on it. BUT! what if I want to make that line blue?Make the line blue. Note that you are giving the line an aesthetic property (the color blue), but you are not mapping that to any values in the data frame, so you don’t put that within the
aes()function:g4 <- g2 + geom_line(data = pv, mapping = aes(x = Date, y = Meters), color = "blue") g4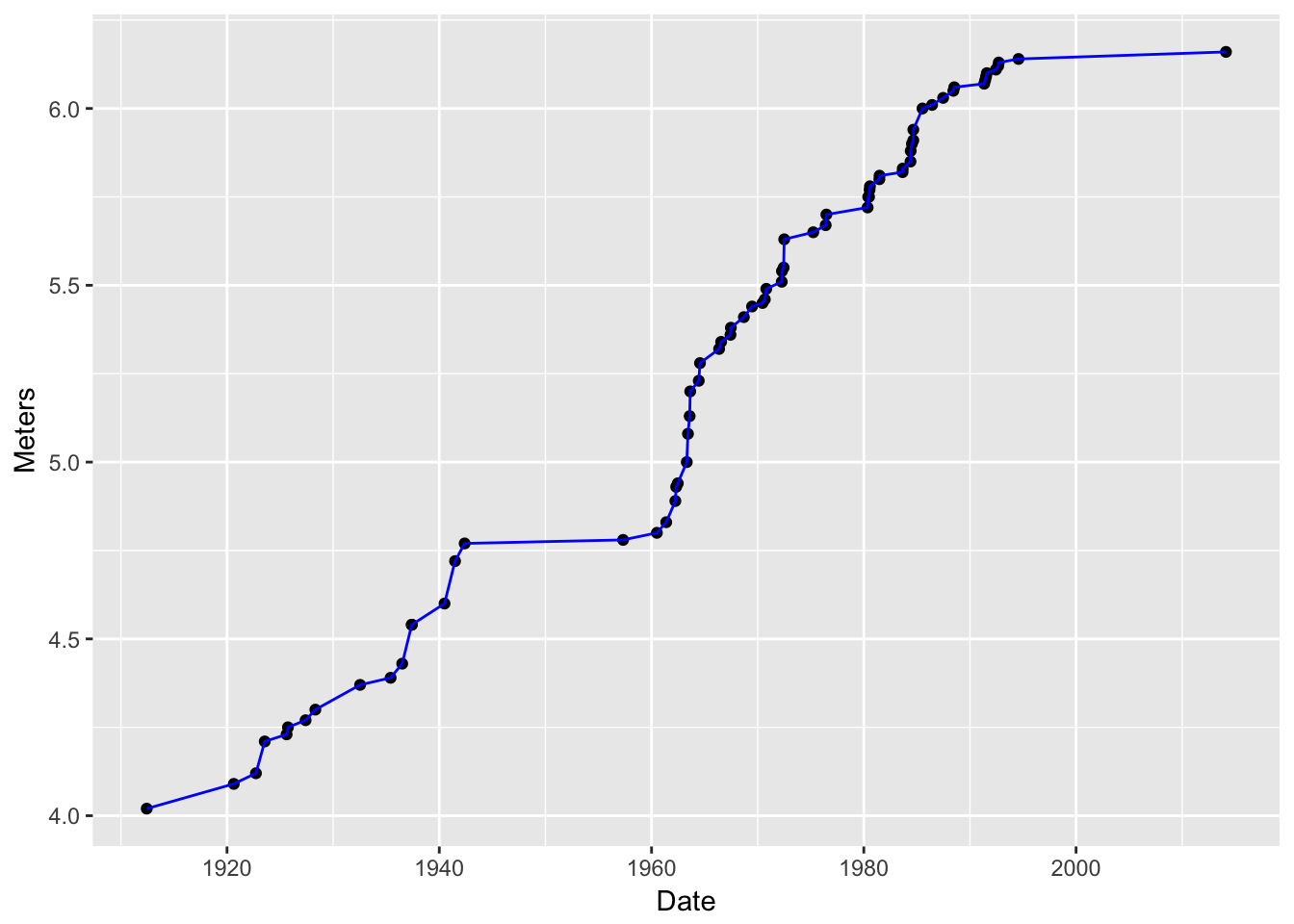
That worked! Notice that we were able to put that new layer atop
g2which we had stored previously.
7.3.3 ggplot’s system of defaults
- Hey! I am really tired of typing
data = pv, mapping = aes(x = Date, y = Meters)isn’t there some way around that? - Yes! You can pass a default data frame and/or default mappings to the original
ggplot()function. Then, if data and mappings are not specified in later layers, the defaults are used. Witness!
d <- ggplot(data = pv, aes(x = Date, y = Meters)) # this defines defaults d2 <- d + geom_point() # add a layer with points d2 # print it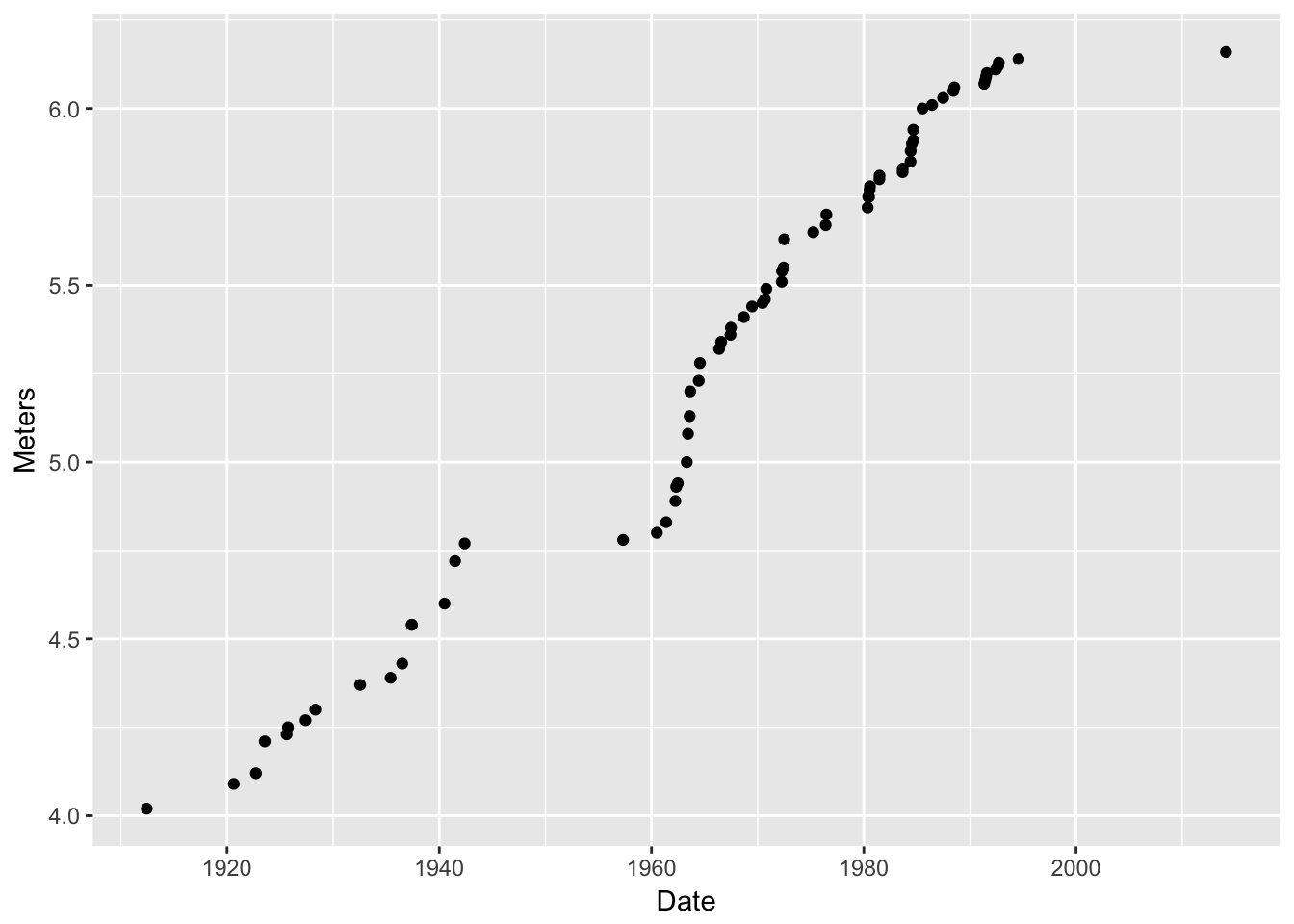
- Sick! Now we can add all sorts of fun layers as we see fit, each time, by invoking a
geom_xxx()function. Let’s go totally crazy!
Establish plot base with defaults:
d <- ggplot(data = pv, aes(x = Date, y = Meters))Add a transparent turquoise area along the back:
d2 <- d + geom_ribbon(aes(ymax = Meters), ymin = min(pv$Meters), alpha = 0.4, fill = "turquoise") d2
Wow! I feel like transparency was never so easy in R base graphics!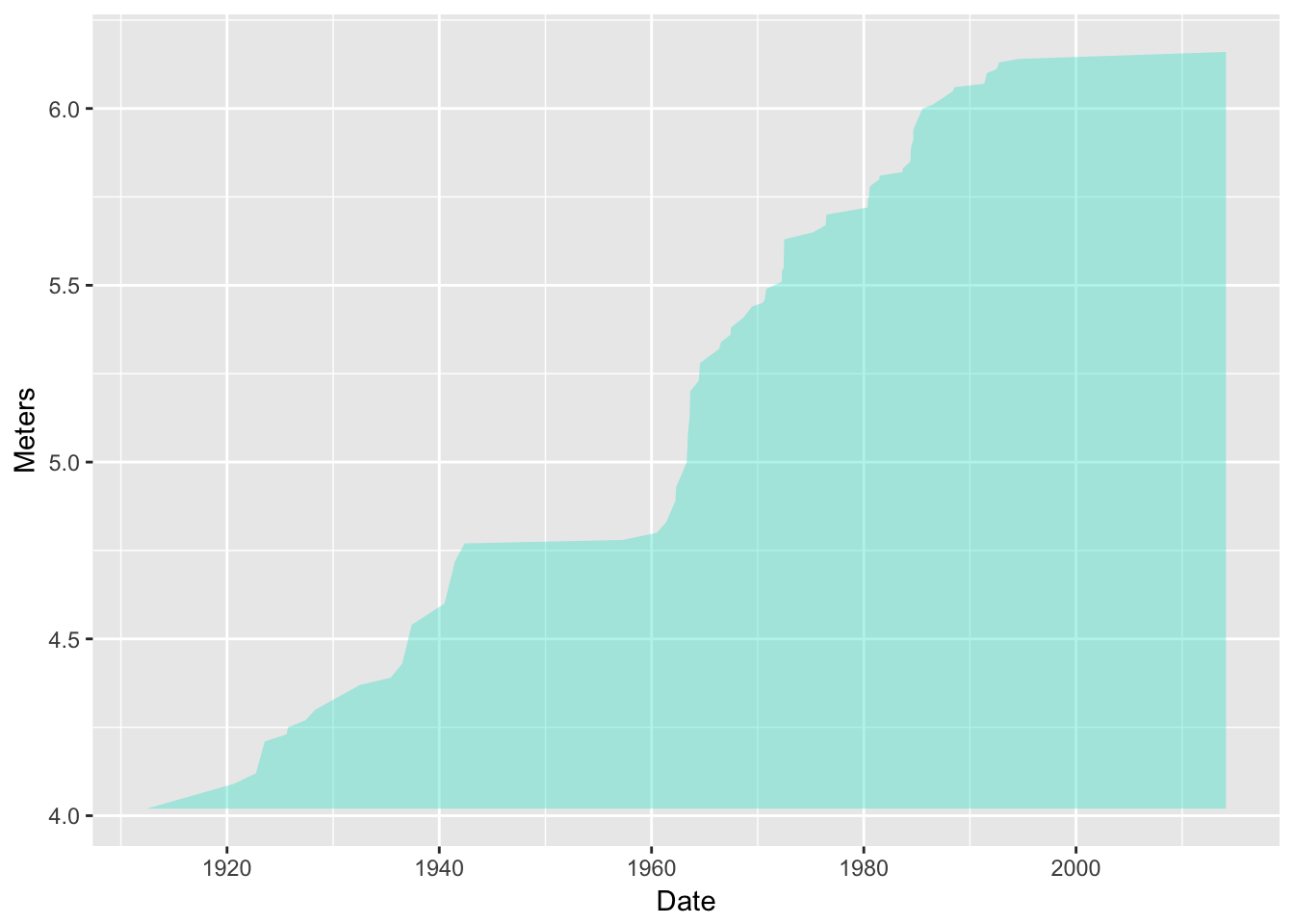
Put a line along there too:
d3 <- d2 + geom_line(color = "blue") d3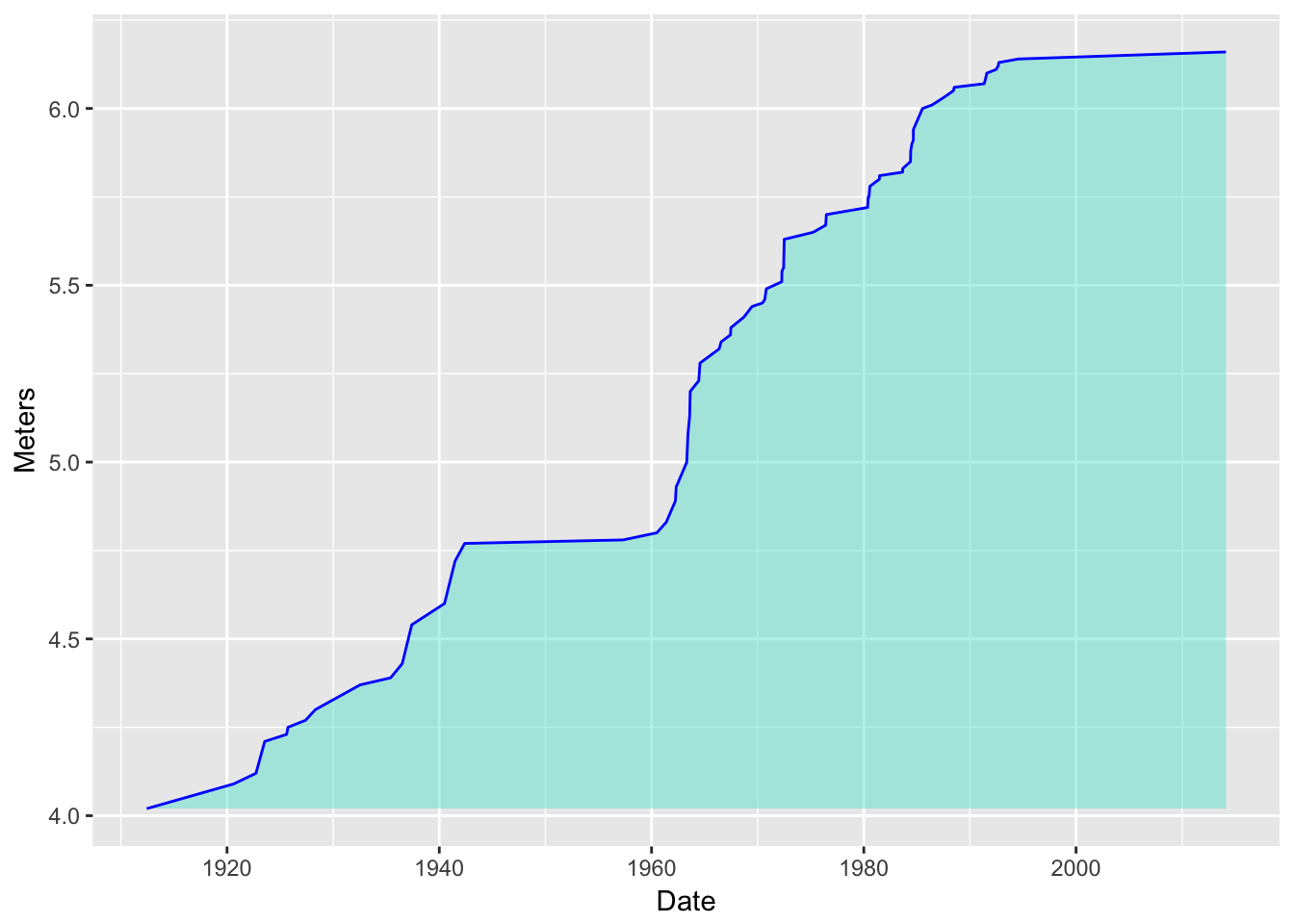
Now add some small orange points:
d4 <- d3 + geom_point(color = "orange") d4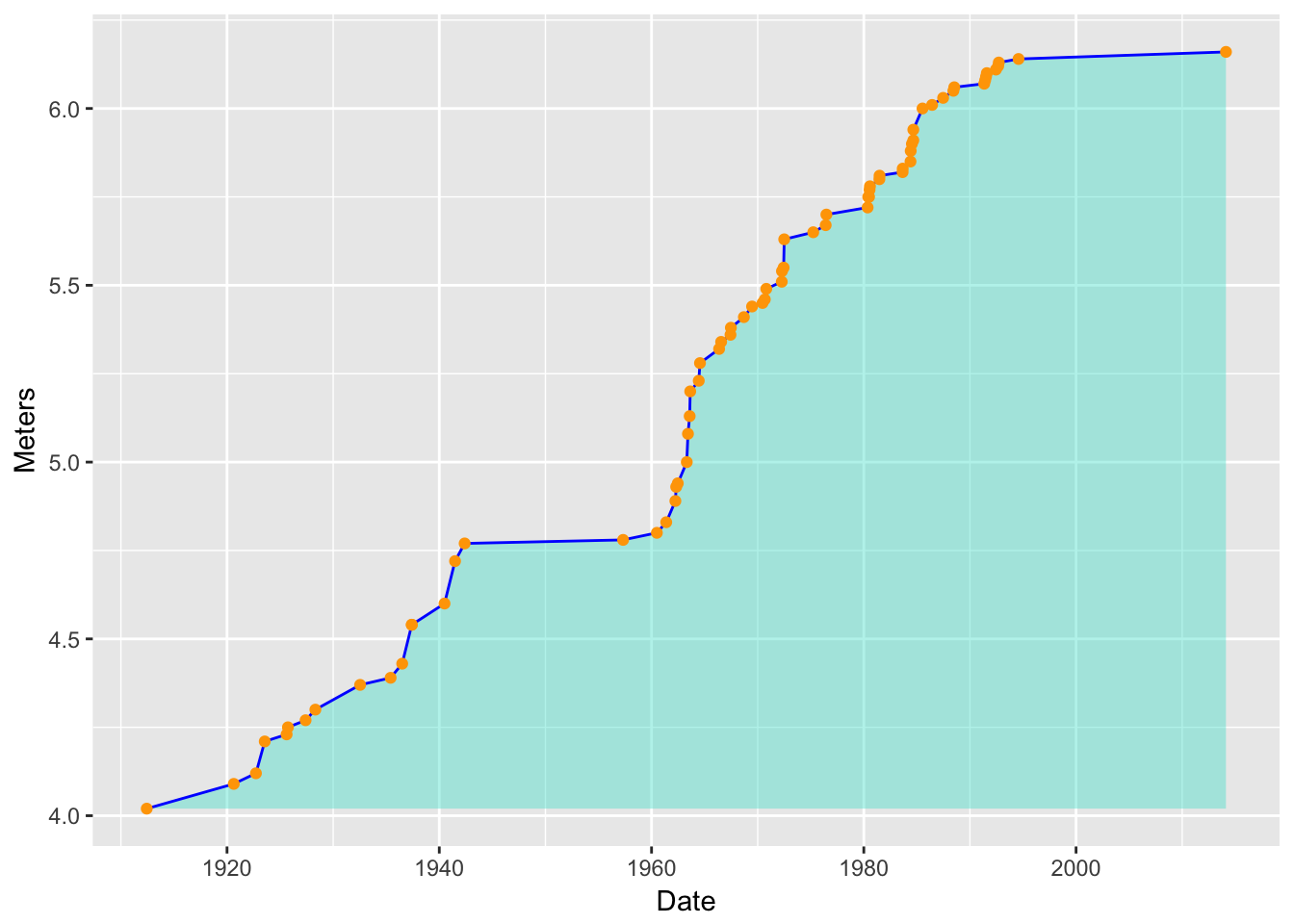
Now, add “rugs” along the \(x\) and \(y\) axes that show the position of points, and in them, map color to Nation:
d5 <- d4 + geom_rug(sides = "bl", mapping = aes(color = Nation)) d5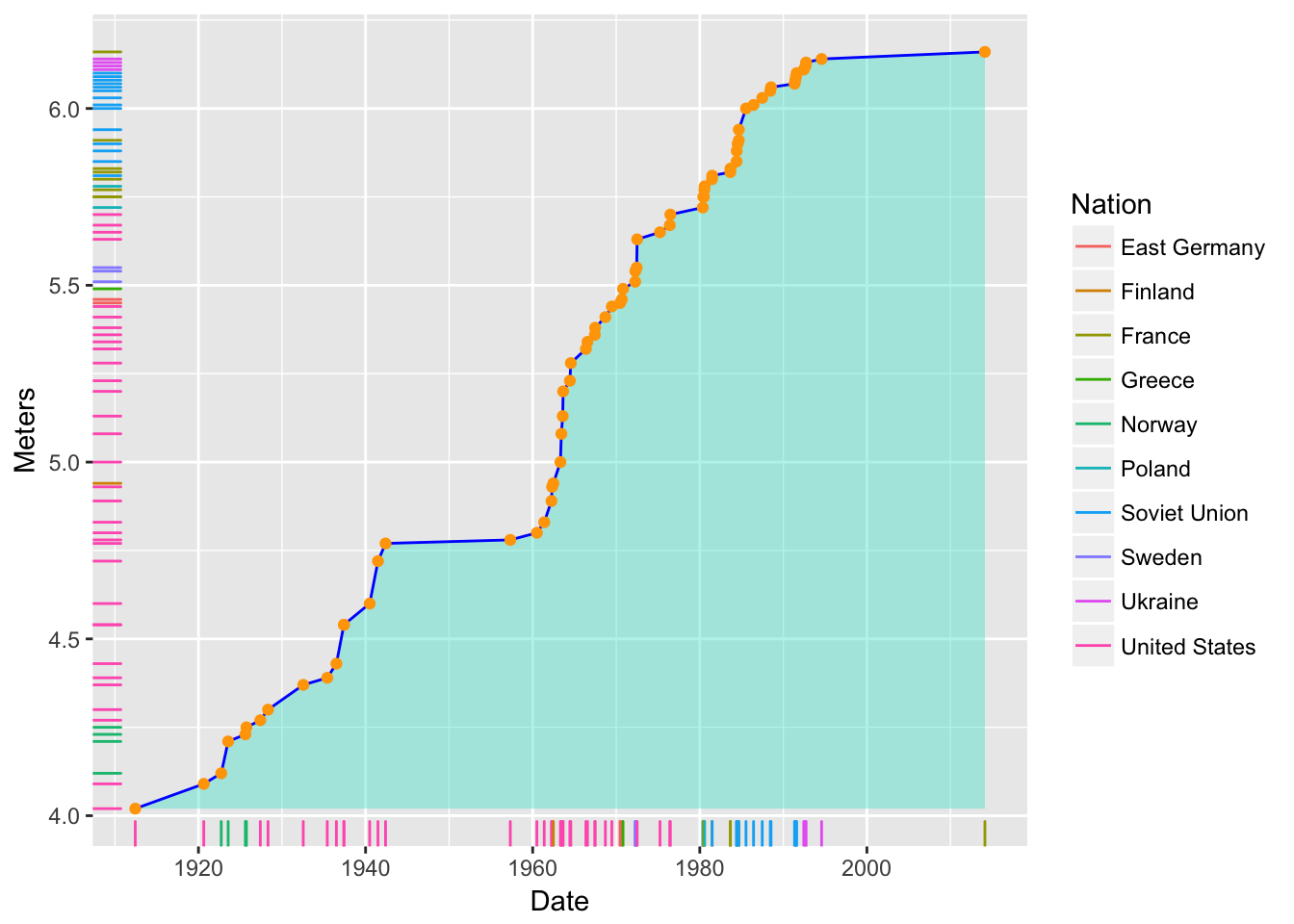
- Note that we are using the
aes()function to add the mapping of color to Nation within thegeom_rug()function.- Note also that the legend was created automatically.
- Wow! A legend is produced automatically, by default, and it looks pretty good. This doesn’t happen without an all-out wrestling match in R’s base graphics system.
- Note that we are using the
- So, that was some fun playing around with the truly awesome ease with which you can build up complex and lovely graphics with ggplot.
7.3.4 How many geoms are there?
- Quite a few. There is a good summary with little icons for each here
- Note that most geoms respond to the aesthetics of
x,y, andcolor(orfill). And some have more (or other) aesthetics you can map values to.
7.3.5 Getting even sillier
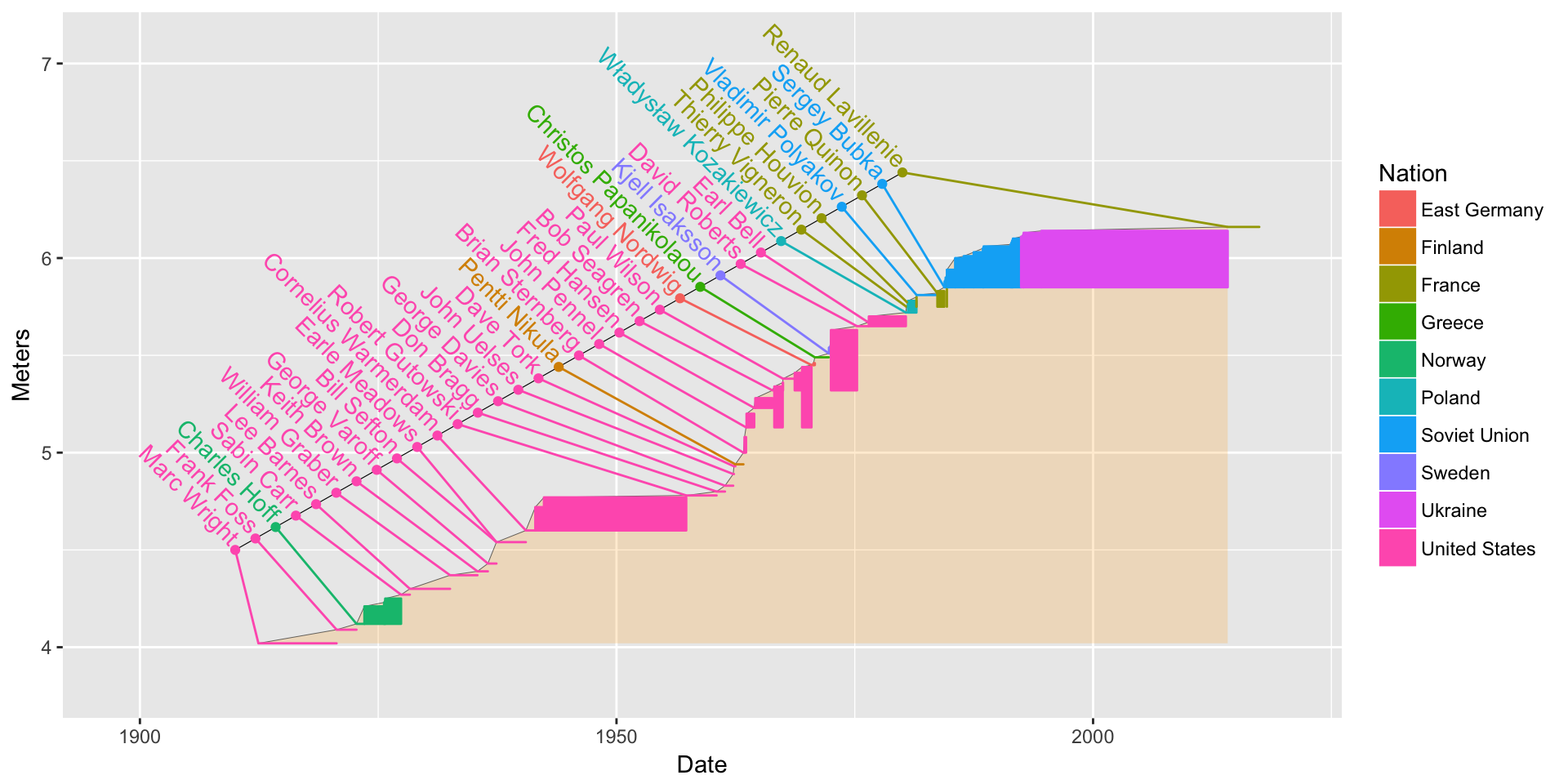
- Here is another plot I made while geeking out.
- I wanted to get a sense for how much individual athletes had improved since their first world record
# add a column for the date of first record for each athlete
pv <- pv %>%
group_by(Athlete) %>%
mutate(FirstRecordMeters = min(Meters)) %>%
ungroup() %>%
mutate(DateNext = lead(Date, default = lubridate::ymd(lubridate::today())))
bb <- ggplot(data = pv, mapping = aes(x = Date, y = Meters, color = Nation)) +
geom_ribbon(aes(ymax = Meters, color = NULL), ymin = min(pv$Meters), alpha = 0.2, fill = "orange") +
geom_line(color = "black", size = .1) +
geom_rect(aes(xmin = Date,
xmax = DateNext,
ymin = FirstRecordMeters,
ymax = Meters,
fill = Nation
))
bb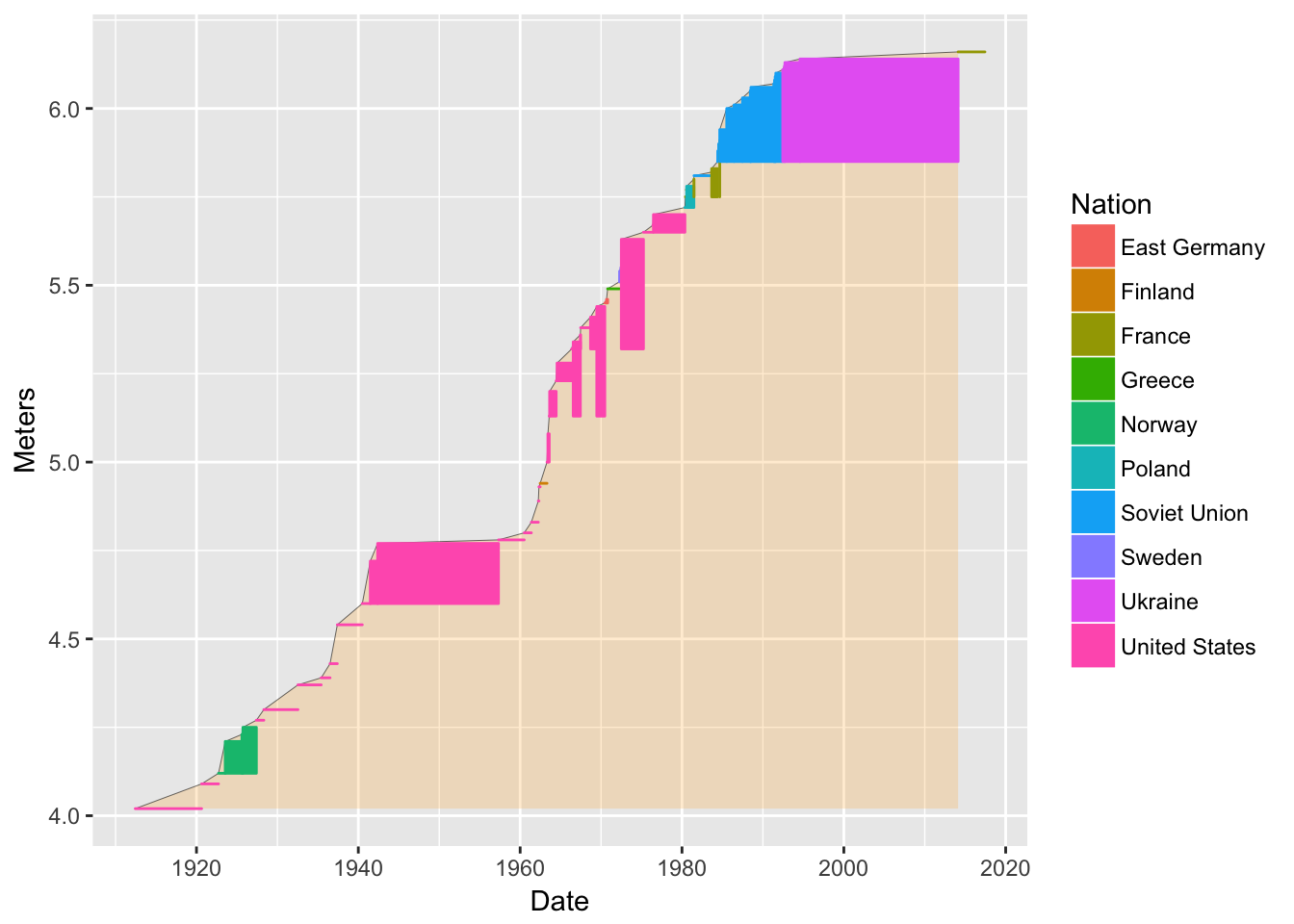
I used geom_rect() to plot rectangles where the bottom edge is situated at the athlete’s lowest world record. Note how it required massaging some data into the data frame at the beginning.
7.3.6 More! Add some text to it!
Now, I want to try to get every single name in the first time the person set the record. Of course, they won’t all fit exactly at the point (Date and Meters) of each record, so let’s space them out evenly, then draw little line segments to meet up with the records.
We make a new data frame that has just the first time a person got a record
pv1 <- pv %>% filter(`#[2]` == 1) pv1 # have a look at it## # A tibble: 34 x 9 ## Record Athlete Nation Venue ## <chr> <chr> <chr> <chr> ## 1 4.02 m Marc Wright United States Cambridge, U.S. ## 2 4.09 m Frank Foss United States Antwerp, Belgium ## 3 4.12 m Charles Hoff Norway Copenhagen, Denmark ## 4 4.27 m Sabin Carr United States Philadelphia, U.S. ## 5 4.30 m Lee Barnes United States Fresno, U.S. ## 6 4.37 m William Graber United States Palo Alto, U.S. ## 7 4.39 m Keith Brown United States Boston, U.S. ## 8 4.43 m George Varoff United States Princeton, New Jersey, U.S. ## 9 4.54 m Bill Sefton United States Los Angeles, U.S. ## 10 4.54 m Earle Meadows United States Los Angeles, U.S. ## # ... with 24 more rows, and 5 more variables: Date <date>, `#[2]` <int>, ## # Meters <dbl>, FirstRecordMeters <dbl>, DateNext <date>Look at the previous plot and decide that we would like to run names equally spaced along a line that runs from about (1910, 4.25) to (1980, 6.5). Note that we will have to squish 34 names along that line. So, we can define the points along it as follows:
pv1 <- pv1 %>% mutate(nameline.x = seq(mdy("1-1-1910"), mdy("1-1-1980"), length.out = nrow(.)), nameline.y = seq(4.5, 6.44, length.out = nrow(.))) pv1$nameline.x <- seq(mdy("1-1-1910"), mdy("1-1-1980"), length.out = nrow(pv1)) # holy cow! did you see how easily we got that sequence of dates? lubridate is amazing! pv1$nameline.y <- seq(4.5, 6.44, length.out = nrow(pv1))Add that line to the plot as colored points atop a black line.
bb2 <- bb + geom_line(data = pv1, mapping = aes(x = nameline.x, y = nameline.y), color = "black", size = 0.2) + geom_point(data = pv1, mapping = aes(x = nameline.x, y = nameline.y)) bb2
Notice how the color of Nation gets applied to the points automatically.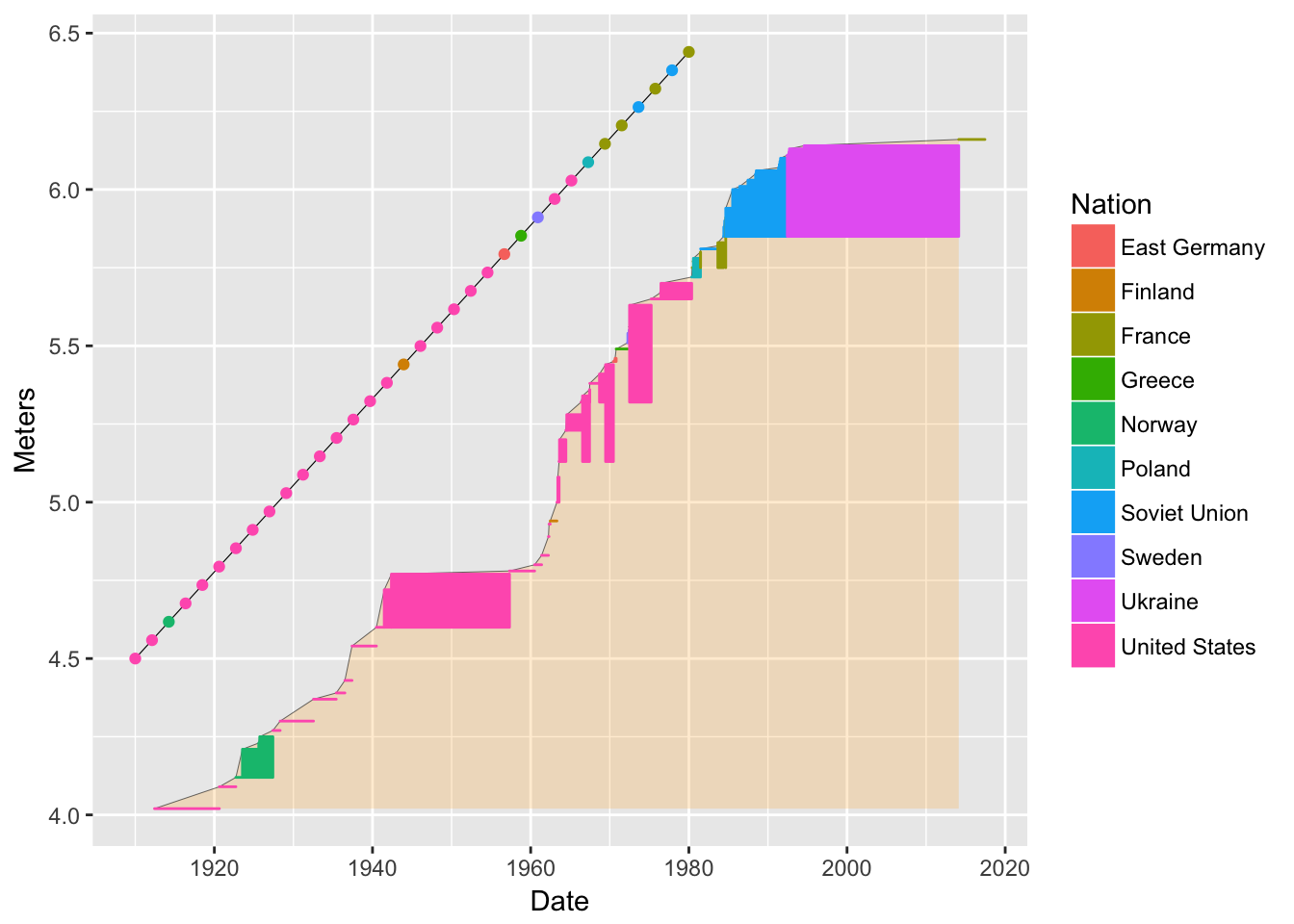
Now, little colored lines from the nameline points to the records. For this we can use the
geom_segment()function.bb3 <- bb2 + geom_segment(data = pv1, mapping = aes(xend = nameline.x, yend = nameline.y)) bb3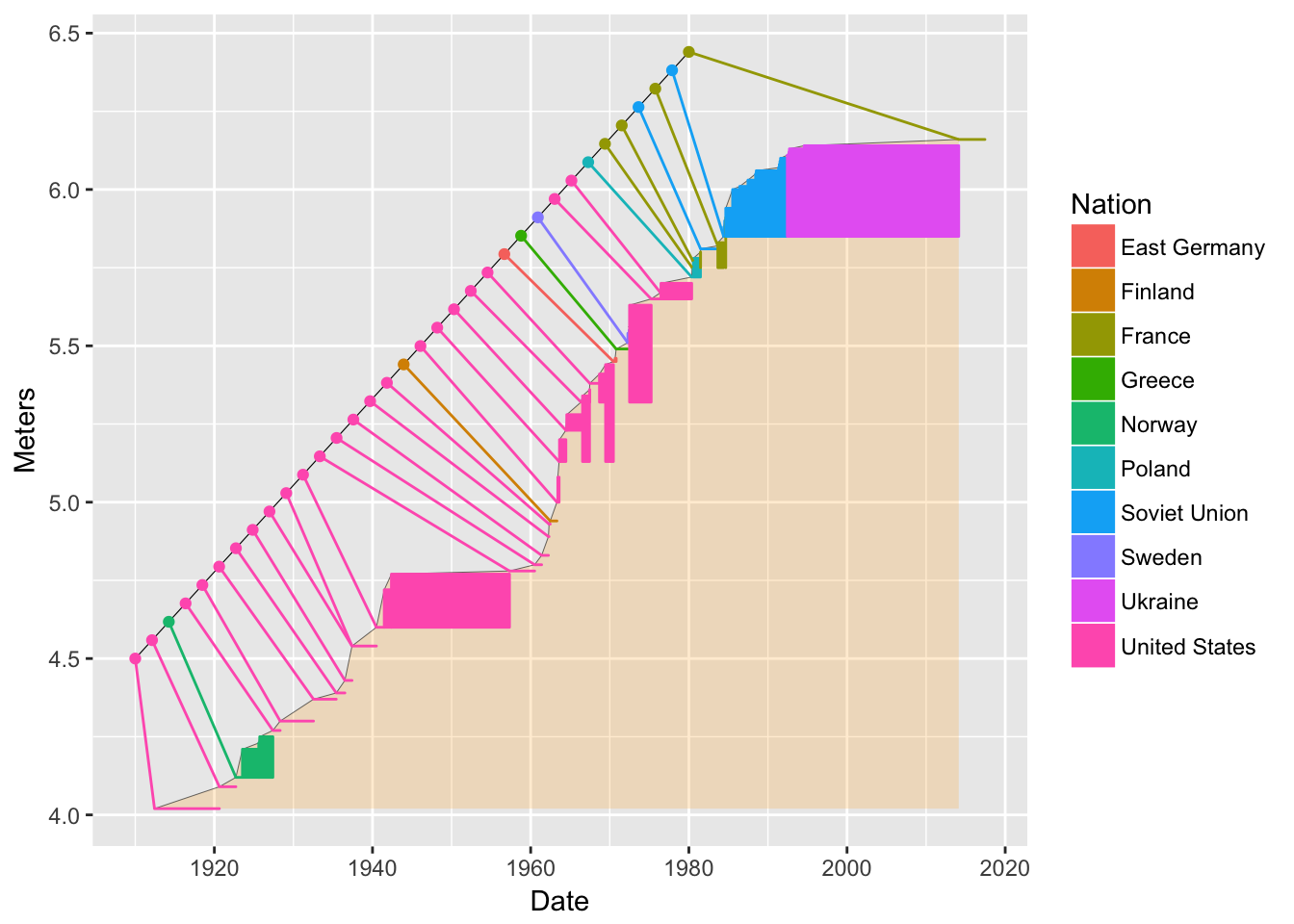
Finally, we want to add the names of the athletes in there. We already have their names in
pv1. We use thegeom_text()function.bb4 <- bb3 + geom_text(data = pv1, aes(label = Athlete, x = nameline.x, y = nameline.y + .05), angle = -45, hjust = 1) bb4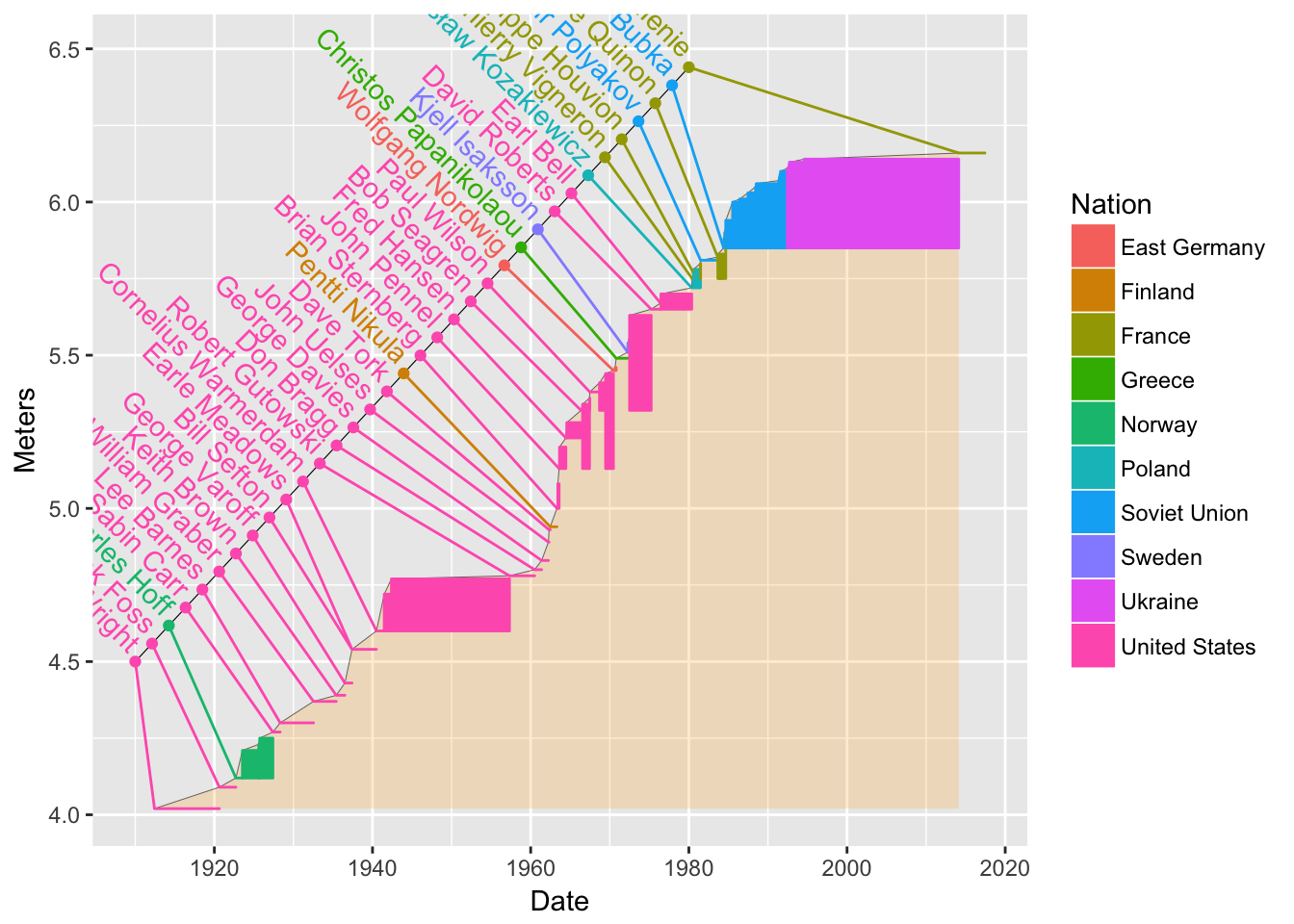
That is pretty cool, but a lot of names have gotten chopped off. Can we do something about that? There might be something a little more automatic, but we can do it by-hand, too:
bb4 + coord_cartesian(xlim = mdy(c("1-1-1898", "1-1-2020")), ylim = c(3.8, 7.1))