CKMRsim-pairwise-relationships
Eric C. Anderson
2024-07-31
CKMRsim-pairwise-relationships.RmdCKMRsim is all about inference of pairwise relationships from genetic
data. This vignette documents the named pairwise relationships that come
“pre-loaded” with CKMRsim. By saying that they are “pre-loaded” we mean
that each relationship’s IBD coefficients are included in the package’s
kappa matrix and that the pedigree specifying the
relationship (for simulating linked markers) is included in the
pedigrees list. Both kappas and
pedigrees are included as part of the built-in data for
this package.
First, we shall print out a table of the identify coefficients for the different relationships.
library(CKMRsim)
library(tibble)
library(dplyr)
library(stringr)
long_names <- c(
MZ = "Monozygotic (identical) twins",
PO = "Parent-offspring",
FS = "Full siblings",
HS = "Half siblings",
GP = "Grandparent-grandchild",
AN = "Aunt-niece",
DFC = "Double first cousins",
HAN = "Half aunt-niece",
FC = "First cousins",
HFC = "Half first cousins",
DHFC = "Double half first cousins",
SC = "Second cousins",
HSC = "Half second cousins",
U = "Unrelated"
)
rtable <- as_tibble(kappas) %>%
mutate(
abbreviation = rownames(kappas),
relationship = long_names
) %>%
select(relationship, abbreviation, everything())
rtable
#> # A tibble: 14 × 5
#> relationship abbreviation kappa0 kappa1 kappa2
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Monozygotic (identical) twins MZ 0 0 1
#> 2 Parent-offspring PO 0 1 0
#> 3 Full siblings FS 0.25 0.5 0.25
#> 4 Half siblings HS 0.5 0.5 0
#> 5 Grandparent-grandchild GP 0.5 0.5 0
#> 6 Aunt-niece AN 0.5 0.5 0
#> 7 Double first cousins DFC 0.562 0.375 0.0625
#> 8 Half aunt-niece HAN 0.75 0.25 0
#> 9 First cousins FC 0.75 0.25 0
#> 10 Half first cousins HFC 0.875 0.125 0
#> 11 Double half first cousins DHFC 0.766 0.219 0.0156
#> 12 Second cousins SC 0.938 0.0625 0
#> 13 Half second cousins HSC 0.969 0.0312 0
#> 14 Unrelated U 1 0 0And now we will show a series pedigrees that depict the relationships, (except for monozygous twins and unrelated, which don’t yield interesting pedigrees) alongside the IBD coefficient values. In these pedigrees, the nodes corresponding to members of the pair are shaded (gray) and are labeled 1 and 2.
Due to the way output files from Mendel are parsed. It is necessary that the members of the pair not be founders in the pedigree. This is why the pedigrees for GP and PO have founders above the oldest members of the pair.



Grandparent-grandchild
\(\kappa_0 = 0.5 ~~~~~~~\kappa_1 = 0.5 ~~~~~~~\kappa_2 = 0\)


Double first cousins
\(\kappa_0 = 0.5625 ~~~~~~~\kappa_1 = 0.375 ~~~~~~~\kappa_2 = 0.0625\)

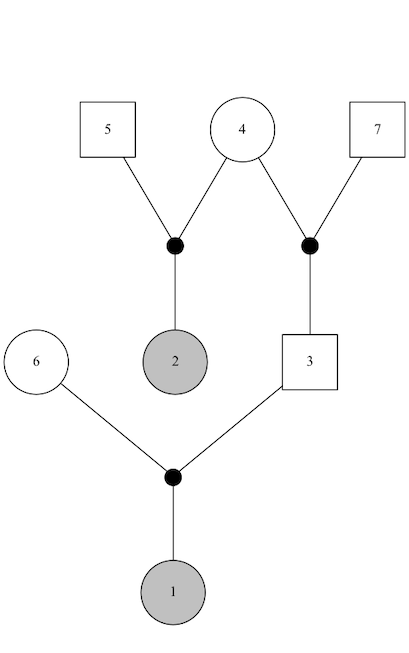

Half first cousins
\(\kappa_0 = 0.875 ~~~~~~~\kappa_1 = 0.125 ~~~~~~~\kappa_2 = 0\)

Double half first cousins
\(\kappa_0 = 0.765625 ~~~~~~~\kappa_1 = 0.21875 ~~~~~~~\kappa_2 = 0.015625\)


